Between two evils I always pick the one I never tried before. - Mae West
虚拟内存的意义
- 对下层: 作为对磁盘上的地址空间的高速缓存
- 对上层:
- 为每个进程提供一致的地址空间
- 保护了不同进程地址空间的相互隔离
地址空间
- 地址空间: 非负整数地址的有序集合
- 虚拟地址空间
- 物理地址空间
- 意义
- 区分地址(属性)和数据对象(字节): 允许每个数据对象有多个独立的地址,其中每个地址都选自一个不同的地址空间
1. 意义一: VM作为缓存的工具
对应着内存层级中的概念,虚拟内存被组织成一个存储在磁盘上的N个连续字节大小的数组。
磁盘和主存之间的存储块被称为页,因而主存可以被视为由内存页构成
- 虚拟内存由虚拟页构成: virtual page
- 物理内存由页帧构成: page frame
1.1. 组织结构
回忆一下,SRAM访问需要几十纳秒,DRAM访问需要几百纳秒,而磁盘访问则为毫秒数量级。因此DRAM不命中开销十分昂贵,所以需要使用高级的替换算法和组织结构以减小不命中率,故而DRAM作为缓存总是被组织成
- 全相联
- 写回
页表
虚拟页到页帧的映射关系被存储在内存中的数据结构 - 页表中。页表是一个页表项(PTE,page table entry)的数组,每一项包含了一些标志位(有效、访问许可、脏)和部分的物理地址。
1.2. 未命中时的缺页处理
当地址翻译硬件读取PTE发现无效时,会触发缺页异常。接着异常处理程序可能会选择一个牺牲页,如果牺牲页为脏页,则会先写回牺牲页。并且会更新牺牲页和缺失页的页表项。接着将缺失的页从磁盘读入牺牲页对应位置。
最后处理器会重新执行导致缺页的指令。
注意: 现代内存系统都仅在页不命中的情况下换入页面,这被称为按需页面调度(demand paging)。
1.3. 分配页
当操作系统分配一个新的虚拟内存页时,它会在磁盘上创建页空间,并更新对应页表项使它指向磁盘上新创建的页面。
1.4. 局部性
表明上看按需页面调度会导致相当大的延迟。但幸运的是,程序往往表现出良好的局部性。
在任意时刻,程序趋向于在较小的活动页面(active page)集合上工作。这个集合被称为工作集(working set)。当工作集的页面被调入内存后,之后对工作集的访问就倾向于命中,而不会产生额外的磁盘流量。
但是,如果工作集大小超过了物理内存大小,则会导致抖动(thrashing)。
注意: Linux中getrusage函数可用于检测缺页的数量。
2. 意义二: VM作为内存管理的工具
由于每个进程有独立的虚拟地址空间,这大大简化了内存的管理。具体而言,
- 简化链接: 独立地址空间允许每个进程的内存映像使用相同的格式,而不用关心具体存放的物理内存位置。
- 简化加载: Linux加载器在加载时只需要将.data和.text段的页表项标记为无效,则在运行时会依靠异常处理程序自动加载。
- 简化共享: 通过将虚拟页面映射到相同的物理页帧,就可以实现内存映射。
- 简化内存分配: 依靠页表维护映射关系,物理页帧就不用存放在连续的地址空间中,而可以分散在物理内存中。
3. 意义三: VM作为内存保护的工具
- 通过维护虚拟页到物理页的映射关系,保护进程的私有内存。
- 通过在页表项上维护更多的许可位能提供更好的访问控制。
- 是否只有内核态能访问
- 读/写权限
4. 原理: 地址翻译
由于将内存地址和地址对应位置存储的数据相互隔离,对给定地址处数据的查询被分成了地址翻译和数据查询两个部分。
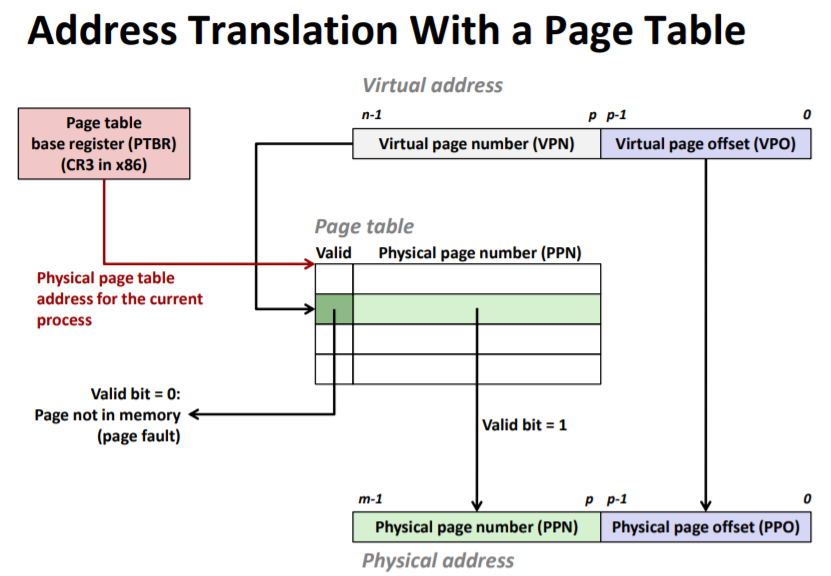
如上图所示,给出了地址翻译的基本原理。概括而言,硬件访问虚拟地址且命中的情况下包括如下步骤
- CPU将虚拟地址给到MMU
- MMU通过页表基址寄存器,注意这里是物理地址,在高速缓存/内存中查询页表
- MMU通过虚拟页号获取到对应的页表项,接着构造物理地址
- MMU根据物理地址再去从高速缓存/内存获取数据
在不命中的情况下
- MMU会触发缺页异常,此时会执行异常处理程序
- 该程序会选择牺牲页并换出到磁盘(若牺牲页为脏页)
- 该程序需要根据缺页的虚拟地址从软件上借助页表进行memory walking,找到页表项后从磁盘调入缺失的内存页,并更新页表项
- 异常处理程序返回后,CPU会重新执行之前导致缺页的指令。
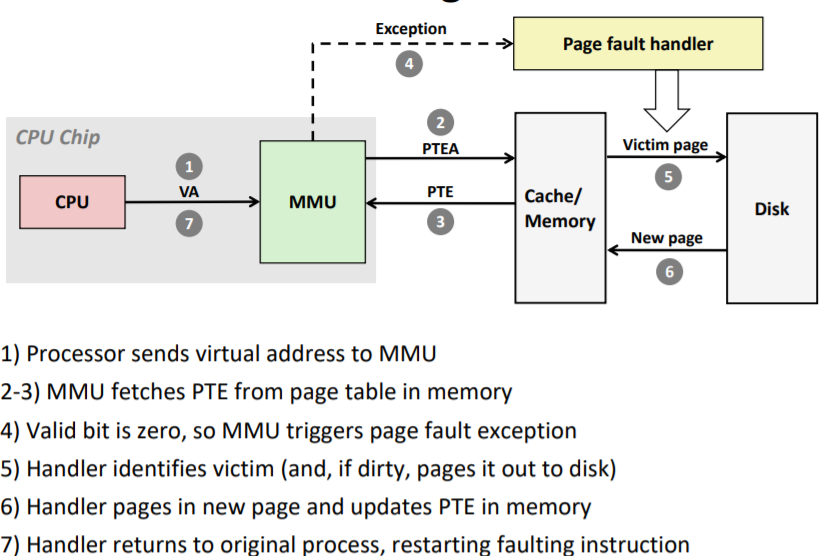
4.1. 虚拟内存与高速缓存
引入虚拟内存后,就需要考虑高速缓存是通过物理地址访问还是通过虚拟地址访问。目前大多数系统均选择使用物理寻址,这种方式有下面的优势
- 简化了多个进程同时在高速缓存中有存储块和共享块的访问问题
- 高速缓存无需处理内存页的保护问题
注意: 使用物理地址访问高速缓存的结果是,地址翻译发生在高速缓存查找之前。
4.2. TLB与地址翻译
CPU每次访存都需要查询PTE,若页表在内存中,则会多访存一次,因而开销增加了几百个时钟周期。若页表在L1缓存中,则需要几个时钟周期的时间。然而很多系统希望进一步减小开销,因此在MMU内部还进一步维护了另一个高速缓存: 翻译后备缓冲器(Translation Lookaside Buffer,TLB)

- TLB是一个虚拟寻址的缓存,每一行包括了一个PTE组成的块
- TLB有高度的相联度
- 由于TLB位于MMU内部,因此翻译速度更快,若TLB未命中,则需要进一步访问L1高速缓存
注意: TLB每一行一般仅包含一个PTE,而L1缓存之类的每一行包含了相邻的多个字节。(真要做应该也可以,集将VPN的低部分几位作为块偏低,但是对应的内存地址相差了一个或多个页大小,可能局部性并不显著?)
4.3. 多级页表
- 使用多级页表的意义
- 如果一级页表中的一个PTE为空,则不需要分配对应的二级页表的空间
- 只有一级页表才需要总是存储在主存中,频繁访问的二级页表才需要调入内存
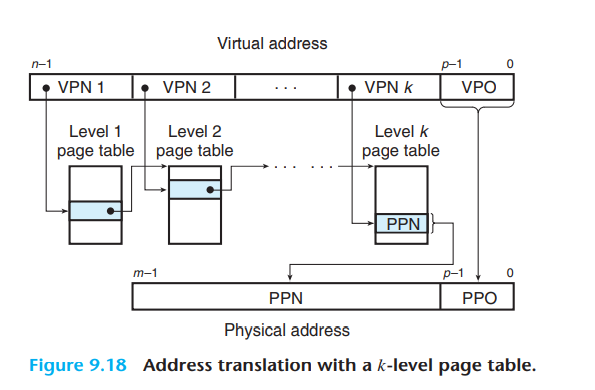
- 在k级页表下,虚拟页号的前k-1部分对应的PTE都是下一级页表的基地址
5. 实例: Core i7与Linux内存系统
5.1. Core i7
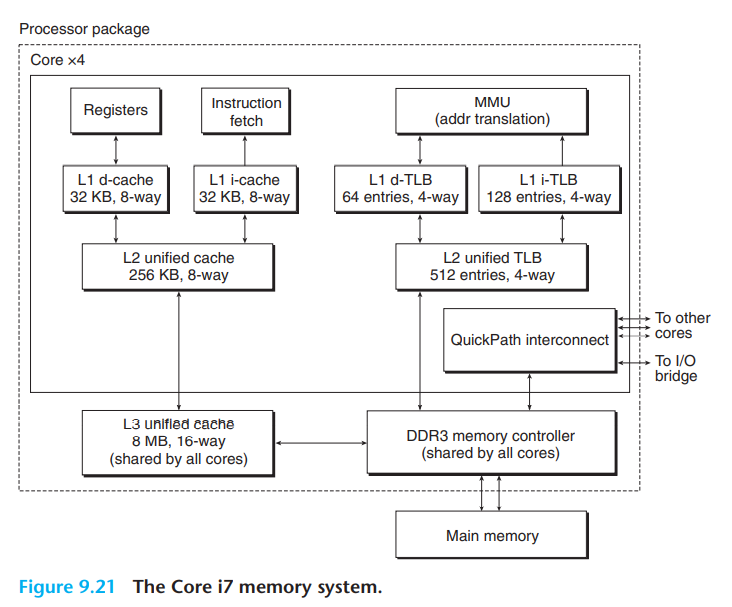
- Core i7内存系统
- 支持48位(256TB)虚拟地址空间
- 支持52位(4PB)物理地址空间
- 主要组件
- 4核
- L1 cache: 32kB,8路组相联,每行64字节,则一共64组
- 所有核共享的L3缓存
- DDR3内存控制器
- 点到点链路: QuickPath技术 - 核间通信、核与外部IO桥通信
- 页大小启动时支持4kB或4MB
- 4级页表
- PTE大小为8字节,40位维护基地址
- 每一页能存储512个PTE,因此一级页表占用地址中的9位索引,48位地址需要4级索引36位,最后12位作为页内偏移
Core i7内存系统整体地址翻译过程如下
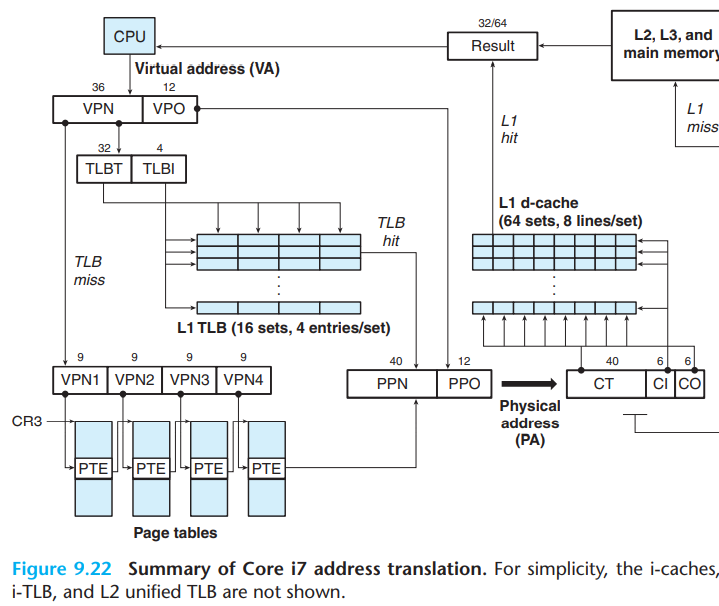
1,2,3级PTE格式
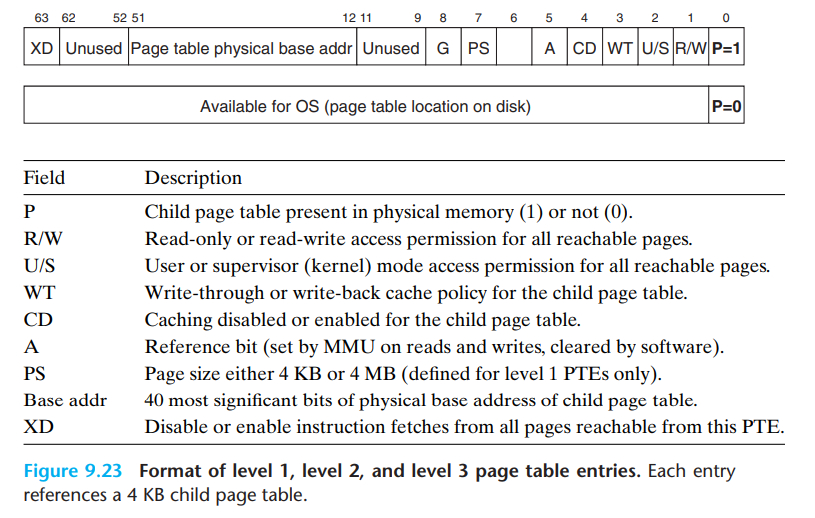
第4级PTE格式

一个PTE包含了三个权限位
- R/W: 读写权限
- U/S: 用户/内核访问权限
- XD: 禁止取指令位,用于限制位于代码段的内存页只读
此外
- A: 引用位(reference bit),用于实现页面替换算法
- D: 脏位,用于表示该页是否被修改
5.1.1. real world
通过之前的讨论注意到
- L1 cache的块偏移为6位,组选择也为6位,剩余为48位的tag
- 一个页大小为4k,因此为12位,这12位表示页内偏移,称为VPO
有意思的是最后这12位对于虚拟地址和物理地址来说是一致的。
因此,当MMU向TLB发送VPN翻译地址时,它会同时发送VPO到L1 cache查找对应的组,并读出对应的8个组中的tag和数据。当MMU翻译VPN得到PPN后,可以就可以直接比对tag。
5.2. Linux虚拟内存系统
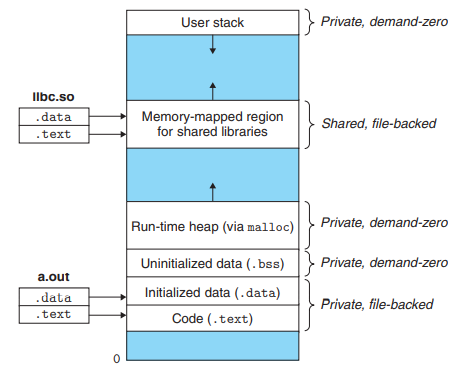
linux系统中为每个进程维护的虚拟地址空间如下
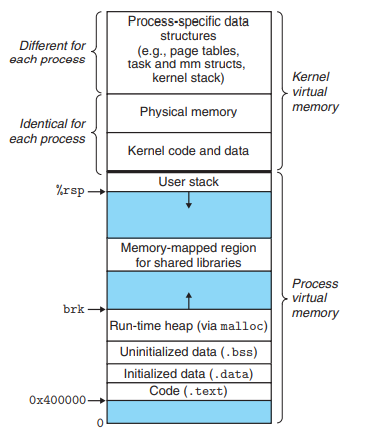
在用户栈之上
- 内核虚拟内存的某些区域被映射到所有进程共享的物理页面
- 内核数据和代码
- 一组连续的虚拟页面被映射到所有DRAM物理内存页,这方便了内核通过虚拟地址直接访问物理地址
- 内核虚拟内存的其它区域被映射到每个进程都不同的数据,例如: 页表、内核栈以及记录当前虚拟地址空间组织的数据结构
5.2.1. Linux虚拟内存组织
Linux将虚拟内存组织成段的集合。已分配的连续虚拟页被称为chunk,每个chunk对应一个段,例如代码段、数据段、堆、共享库段等。
Linux通过链表组织段结构。
如下图,每个Linux进程有唯一的一个task_struct结构体,改结构体中包含了PID、指向用户栈的指针、可执行目标文件的名字、程序计数器等信息。其中一个条目指向mm_struct该条目描述了虚拟内存的当前状态,其中pgd给出了页表基址的值,mmap指向了vm_area_structs链表,其中的每个vm_area_structs都描述了一个段。具体而言,每个vm_area_structs包含了
vm_start: 段起始的虚拟地址vm_end: 段结束的虚拟地址vm_prot: 段内所有页的读写权限vm_flags: 段内页面的私有/共享以及其它属性信息vm_next: 指向下一个段
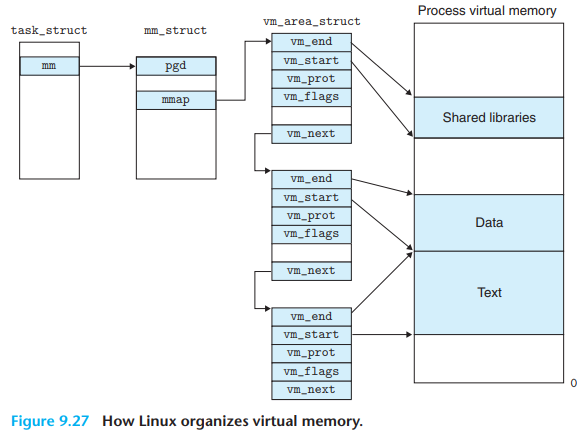
5.2.2. Linux缺页异常处理
当MMU试图翻译某个虚拟地址触发缺页异常时,会执行下面的步骤
- 判断地址是否合法?
- 通过上述链表查找,并比较
vm_start和vm_end。实际上Linux会将该链表组织成搜索树的形式以加快查找的速度
- 通过上述链表查找,并比较
- 内存访问是否合法?
- 即是否有读/写/执行权限
- 选择牺牲页,并交换到磁盘,然后调入新页并更新页表
6. 应用: 地址映射
Linux通过虚拟内存区域/段管理虚拟内存,在虚拟内存区域和磁盘上的对象间建立映射关系的过程被称为内存映射。虚拟内存区域可以映射到下面两种类型的对象:
- Linux文件系统中的普通文件
- 段可以被映射到一个普通磁盘文件的连续部分(注意: 这里不需要是整个文件),例如一个可执行目标文件
- 由于按需分页,建立映射关系后,仅在应用程序引用对应虚拟地址时,才会真正调入页面
- 匿名文件: 请求二进制零的页(demand-zero page)
- 段可以被映射到一个匿名文件,匿名文件由内核创建,包含二进制零,
- 注意: 该匿名不真正存在于磁盘上
此外内核还会维护一个磁盘上的交换空间,用于存放牺牲页。
注意: 每个区域都可以映射到不同的对象,例如代码段和数据段虽然映射到的是同一个文件,但是作为两个独立的区域进行映射。
6.1. 共享对象
能够和虚拟内存区域建立关联关系的对象有以下两种
- 共享对象: 和共享对象关联的虚拟内存区域被称为共享区域
- 写操作可见性: 对共享对象的写,其它进程可见,且会反应在磁盘上的原始对象中
- 共享对象只有一个物理副本
- 私有对象: 和私有对象关联的虚拟内存区域被称为私有区域
- 写操作的可见性: 对私有对象的写,其它进程不可见,且不会反映在磁盘上的原始对象中
- 私有对象通过写时复制的技术被映射到内存中
- 私有对象对应的虚拟页被标记成只读
- 维护虚拟内存区域的数据结构被标记成私有的写时复制(COW)
注意: 每个对象都有唯一的文件名,因此内核能够判断当前是否有其它进程映射了相同的对象。
6.2. fork
内核执行fork函数时,包括了下面的步骤
- 分配PID
- 以当前进程的
mm_struct、区域结构、页表作为副本创建新的进程管理结构 - 将两个进程所有页面标记为只读
- 将两个进程的所有段标记为私有的写时复制
6.3. execve
当前进程执行execve函数时,主要包括下面的步骤
- 删除已存在的用户区域
- 映射私有区域
- 新程序的代码、数据、bss、栈区域都是私有且是写时复制的
- 代码和数据区域被映射到
a.out文件的.text和.data区 - bss区域是请求二进制零的,映射到匿名文件,大小包含在
a.out文件中 - 栈和堆也是请求二进制零的,初始大小为0
- 映射共享区域
- 共享对象动态链接到程序,再映射到虚拟地址空间中的共享区域
- 设置程序计数器指向代码区域的入口点
6.4. mmap系统调用
1 | |
mmap函数请求内核创建一个新的虚拟内存区域,最好是从地址start处开始。并将fd指定的对象的一个连续的片映射到这个区域。连续的片的大小为length字节,从距文件offset字节处开始。其中,start常常设置为NULL,表示由内核决定映射的虚拟区域位置。
prot给出了这个区域的访问权限位,最终会存储在分配的内存区域的vm_prot中
- PROT_EXEC: 可执行
- PROT_READ: 可读
- PROT_WRITE: 可写
- PROT_NONE: 这个区域的页不可被访问
flags给出了被映射对象的类型
- MAP_ANON: 请求二进制零的匿名对象
- MAP_PRIVATE: 私有、写时复制的对象
- MAP_SHARED: 共享对象
对应的删除虚拟内存区域的系统调用为
1 | |