Don’t worry if it doesn’t work right. If everything did, you’d be out of a job.
相比于使用底层的mmap和munmap,使用动态内存分配器进行运行时内存分配具有更好的移植性。
动态内存分配器有两种实现风格:
- 隐式内存分配: 即垃圾回收器,分配器会主动释放不再使用的内存块。
- 显示内存分配: 例如c库的malloc程序包,应用需要显式释放之前请求的内存。
堆内存
堆内存的内存布局如下
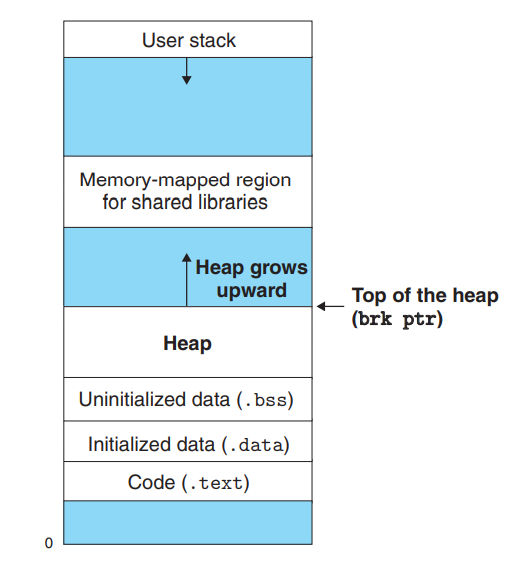
- 从内核的视角,其为每个进程维护了一个
brk变量,指向堆的顶部。 - 从分配器的视角,它将堆组织为一个内存块的集合,每个内存块存在两种状态:空闲和已分配。
- 分配器的本身通过
mmap或是void *sbrk(intptr_t incr);从内核获取空间。
注意: 对于malloc函数,若使用gcc -m32编译,则malloc返回的块的地址总是8的倍数 (同时需要填充,保证空闲块是双字边界对齐,即实际分配大小也是8的倍数,注意这里是实际分配大小!!payload大小可能不是8的倍数!!);若使用gcc -m64,则malloc返回的块的地址总是16的倍数。
- 返回块的地址是8的倍数,而不是分配块的起始地址
1. 显示内存分配器的需求和目标
尤其需要注意下面的块对齐要求!
- 处理任意的请求序列: 只要保证释放请求对应之前的分配块,则应用可以有任意的分配请求和释放请求序列。分配器不能对请求的到来顺序做出假设。
- 主动响应请求: 分配器不能为了性能主动缓存或者重排请求。
- 只使用堆: 分配器使用的任何非标量数据结构都必须保存在堆里,包括用于维护内存块集合的数据结构。
- 对齐块: 分配器必须对齐块。对齐有两个要求,这里以32 byte-aligned为例
- 分配块的payload起始地址需要为32的倍数
- 整个分配块(payload+overhead)的大小需要为32的倍数
- 不修改已分配块: 分配器只能处理空闲块。
接下来看一下内存分配器设计的目标:最大化吞吐量和内存利用率。
- 目标1: 最大化吞吐率。单位时间里完成的请求数应当尽可能多,一般而言,等价于最小化请求处理的平均时间。
- 目标2: 最大化内存利用率,具体而言,使用峰值利用率(peak utilization)
给定n个分配请求和释放请求的序列: R0, R1, R2, ..., Rk, ..., Rn-1。若一个分配请求需要p字节的块,则称得到的已分配块的有效载荷为p字节。在Rk完成之后,称Pk为aggregate payload,即当前已分配的有效载荷之和,Hk表示堆的前k+1个请求的最高峰,则峰值利用率为
注意: 这里是有效载荷,不包括分配器的填充。
碎片
- 内部碎片: 已分配块比有效载荷大。为了满足对齐,或是分配器的实现本身强加了块大小。
- 注意: 内部碎片仅取决于之前请求的模式和分配器的实现方式。
- 解决: 尽可能减小用于维护的相关数据结构的大小。
- 外部碎片: 空闲块内存之和满足分配请求,但是不存在单独的空闲块足够满足当前请求。
- 注意: 外部碎片难以量化,除了之前请求的模式和分配器的实现方式,还取决于将来请求的模式。
- 分配器通常使用启发式策略维护少量的大空闲块。
- 解决: 采用好的block placement启发式策略。
1.1. 实现
实现动态内存管理时,需要解决下面这些问题:
- 数据结构: 空闲块组织
- 分配请求:
- 如何选择空闲块作为分配块
- 如何处理新分配块造成的空闲块分割问题
- 释放请求: 如何合并已经释放的分配块
1.1.1. 实现1: 隐式空闲列表
隐式空闲链表: 通过在分配块头部存储长度信息,隐式给出空闲块链表。当需要遍历整个空闲块集合时,分配器需要遍历所有空闲块和已分配块。内存块的结构如下:
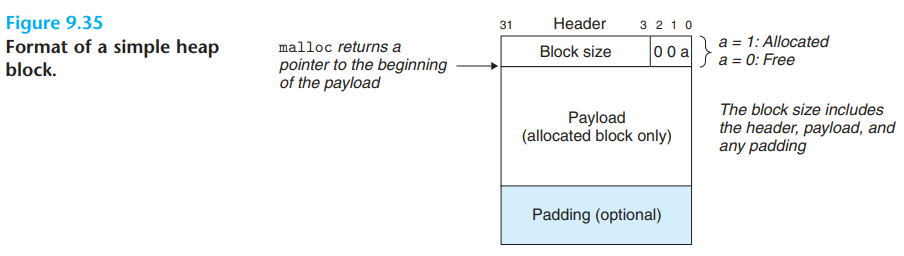
1 | |
- 数据结构
- 大小字段: 头部为4字节
- 标记: 使用隐式空闲链表的方式下,为了满足对齐要求,最小的内存块也需要为8字节。因此内存块大小字段的低3位用于表示是否分配
- 最小块大小限制: 当k字节的分配请求到来时,若能正常处理,分配器需要消耗(k + 4)向上取整为8的倍数的内存大小。例如,
malloc(1)需要消耗8字节,malloc(13)需要消耗24字节。- 更通用的说,这里的4其实是所有开销字节之和,因此也可能取到其他值。
分配请求
- 首次适配: 每次分配均从头开始搜索空闲链表
- pro: 较大空闲内存块位于链表尾部
- con: 链表起始处会有较多碎片,因此增加对较大块的访问时间
- 下一次适配: 每次分配从上一次分配处开始搜索
- pro: 相比于首次适配,运行的更快
- con: 内存利用率低于首次适配,最优适配内存利用率最高
- 最优适配: 每次分配检查所有空闲块,选择适合所需请求的最小内存块
- pro: 吞吐量最差
- con: 内存利用率最高
释放请求
- 合并(coalescing)
- 立即合并: 对每个释放请求尝试合并。
- 推迟合并: 当分配请求无法满足,扫描整个堆,然后合并。或是采用其它启发式的方式。
- 立即合并的实现
- 合并下一个空闲块: 注意到上图的结构相当于一个单链表,因此对下一个块是否空闲可以很容易检查
- 合并上一个空闲块
- 边界标记: 改变为双链表,即每个内存块增加一个尾部,其值和首部相同
- 改进: 注意到仅在前一个为空闲的情况下需要合并前一个,因此考虑将前一个的状态维护在当前块的标记内。同时空闲块需要保留尾部,而已分配块不需要维护。
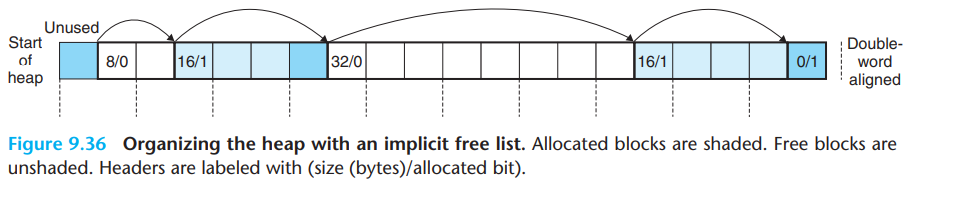
注意:
- 为了满足返回块地址在双字边界上,第一个字作为填充。
- 同时结尾块(epilogue block)只需要一个字。在heap的总大小增加时,结尾块会作为新到来的空闲块的首部。
1.1.2. 实现2: 显式空闲链表
显式空闲链表: 将空闲块的空间组织成显式的链表。例如将空闲块组织成双链表,指向前后空闲块的指针存放在空闲块中,如下。
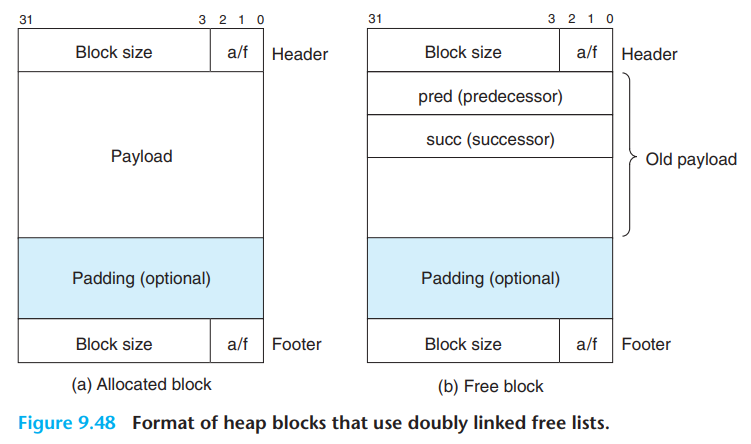
此时,首次适配的时间为空闲块的数目,而非所有内存块的数目。释放时间则取决于释放策略:
- 后进先出: 将新释放的块放在链表头
- 常数时间定位,若使用边界标记,则也是常数时间合并。
- 按内存顺序: 链表按内存地址顺序存放
- 释放需要线性时间以找到前驱。
- 内存利用率较高。
很明显,显式空闲链表的缺点是空闲块的最小大小必须足够大(以装下指针以及相关数据),等价地,这导致最小分配块大小也较大,因为是由空闲块分割获得,因此提高了内部碎片出现的可能。
1.1.3. 实现3: 分离的空闲链表
idea: 将所有可能的内存块大小划分为等价类,也称作大小类(size class)。例如: {1}, {2}, {5~8}, {…}, {1025~2048}, {4097~}
分离存储(segregated storage): 分配器维护多个空闲链表,每个链表中有大小大致相等的空闲内存块。
- 简单分离存储: 每个大小类包含相同大小的内存块,且不会有分割和合并操作。
- 外部碎片较大
- 分离适配: 每个大小类包含不同大小的内存块
- 最佳适配的近似: 极端情况下,若每个大小一个类,则为最佳适配
- 利用率好: 在一个内存块范围内寻找,而非遍历所有
- 吞吐量更高: 针对2的幂次大小的类log时间 vs 线性时间
- 伙伴系统: 是分离适配的一个特例,具体而言,每个空闲块为2的幂次大小,并以此组织为空闲链表。一个内存块和它的伙伴只有1位差异。
1.2. 分配器策略小结
- placement policy
- first-fit, next-fit, best-fit, etc
- 低吞吐量和较小碎片的折衷
- 分离空闲列表: 不需要搜索整个空闲列表的近似最佳placement policy
- splitting policy
- 什么时候需要分割空闲块?
- 能够容忍多少外部碎片?
- coalescing policy
- Immediate coalescing: 每次free调用就会尝试合并
- Deferred coalescing: 提高free的性能,在需要的时候再合并
2. 垃圾收集: Mark & Sweep算法
2.1. 基本结构
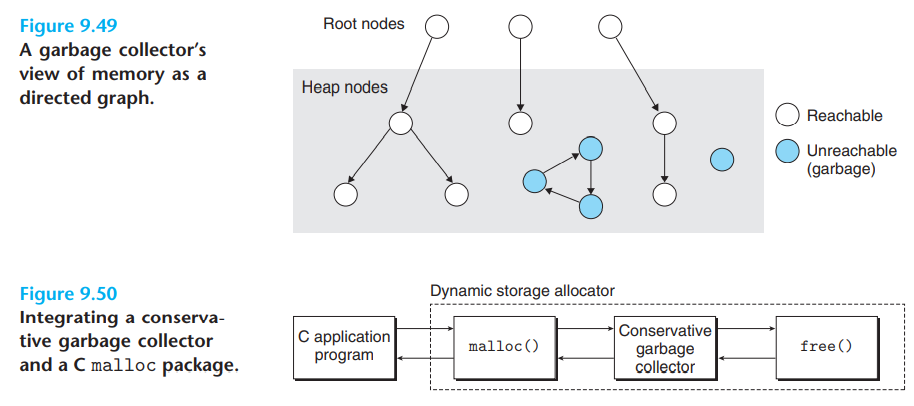
如图,根节点为指向堆中内存的指针,它们可能存在于
- 寄存器中
- 栈中
- 虚拟内存读写区域的全局变量中
对于堆中从根节点不可达的内存块,它们均为垃圾。
此外,当调用malloc时,若没有足够的内存块能够满足请求,则malloc函数会调用垃圾回收器,垃圾回收器进而会调用对垃圾块的free()。
2.2. Mark & Sweep
Mark & Sweep算法包括两个阶段。
第一个阶段标记
- 从每个根节点开始,标记可达的第一个节点
- 接着对该节点内存块中的每个字(false positive)递归调用标记算法
第二个阶段清除
- 遍历堆中每一个分配块,若它们没被标记,则将它们清除。
注意:
- 由于垃圾回收器需要判断输入值是否指向有效载荷的某个位置,因此需要用平衡二叉树(红黑树)维护已分配的内存块地址,以保证
- 左子树中所有块都放在低地址处,右子树中所有块都放在高地址处
- 注意: 此时已分配块头部中需要维护指向左子树的指针和指向右子树的指针
- 由于C语言不维护内存中值的类型信息,因此会导致对可达情况的false positive问题。例如,某个int数据的值恰好和另一个不可达内存块地址相同,则会错误标记后者可达。
3. 内存管理与指针
如上,需要注意:
*size--等价于*(size--)
