Lock or non-blocking?
1. fine-grained synchronization
- How are the operations atomic? x86 Lock prefix
- if the memory location is cached, then the cache retains that location until the operation completes
- keep owning a cache line
- if not
- bus: the processor uses the lock signal and holds the bus until the operation completes
- other design: the processor NACKs any request for the cache line until the operation completes
- note: operations must be made on non-overlapping addresses
- lock cmpxchg
- lock ts
- if the memory location is cached, then the cache retains that location until the operation completes
Build an atomic fetch+op out of atomicCAS()
1 | |
1.1. sorted single linked list
idea: using fine-grained lock for each node. And while traversing the list, grab two consecutive nodes’ locks (prev and cur) at a time and use hand-over-hand locking. (….monkey-bar….)
- goal: enable parallelism in data structure operations
- different parts of the data structure might be able to proceed in parallel
- costs
- overhead of taking a lock each traversal step
- extra storage cost
2. Lock-free programming
- a blocking algorithm allows one thread to prevent other threads from completing operations on a shared data structure indefinitely.
- 不管是否使用忙等或者抢占,阻塞算法都可能导致无限期等待,例如锁的持有者崩溃、被OS换出等等。
- mutual exclusion
- lock-free = non-blocking
- lock free: some thread is guaranteed to make progress even if some other may crash(“systemwide progress”)
- not possible to prevent progress
- note: starvation is still possible
- eg: atomic add
2.1. lock-free queue
- single reader, single writer bounded
- only two threads (one producer, one consumer)
- no need to use lock
- single reader, single writer unbounded
- main idea: allocation and deletion performed by the same thread, i.e. only one thread can modify the shared structure
- use reclaim pointer and let pusher to reclaim the memory
2.2. lock free stack
2.2.1. buggy implementation
1 | |
- ABA problem: when calling pop(), the old_top may first be poped than pushed again, and if there are other push operations executed in between, then the pop() will cause some data loss
- reason: use node address as identifier, but what if node has been deleted and recycled
2.2.2. ABA solution: using double/wide CAS
1 | |
- real world
- cmpxchg8b: compare and exchange 8 bytes
- cmpxchg16b: compare and exchange 16 bytes
2.2.3. another problem: referencing freed memory
- what if top is NULL when executing
Node *new_top = top->next - using hazard pointer to maintain the node that each thread is accessing, and the thread which is responsible for releasing the node only delete it after there is no other thread still reference the node

2.2.4. lock-free linked list insertion
- only insertion operation, then no ABA problem
1 | |
2.3. Lock-free vs. locks: performance comparison
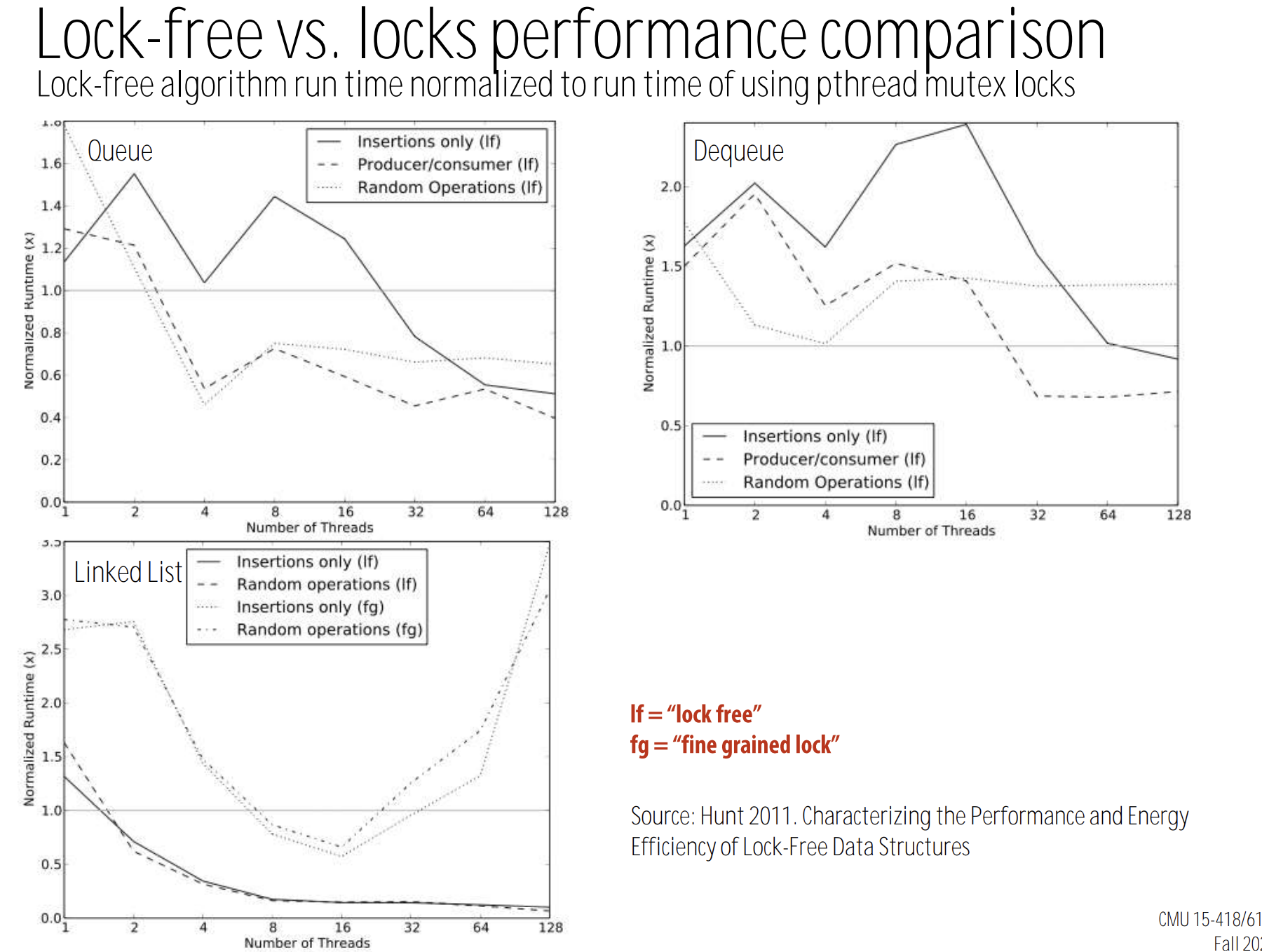
- hot-spot for deque and queue
- when the number of threads increases, the performance of lock-free version tends to be better
3. summary
- fine-grained locking: reduce contention (maximize parallelism) in operations on shared data structures
- lock-free data structures: non-blocking solution to avoid overheads due to locks
- caveat: a lock-free design does not eliminate contention
- compare-and-swap can fail under heavy contention, requiring spins