Perfect is the enemy of the good.
1. basic framework
- acquire method: how threads gain access to the protected resource
- waiting algorithm: how threads wait for access to be granted
- release method: how threads enable other threads to gain resource
2. lock implementation
1 | |
load-test-store can not guarantee atomicity.
2.1. test-and-set lock
idea: atomically read and write
1 | |
Every lock operation needs to issue BusRdX even if they can not acquire the lock.
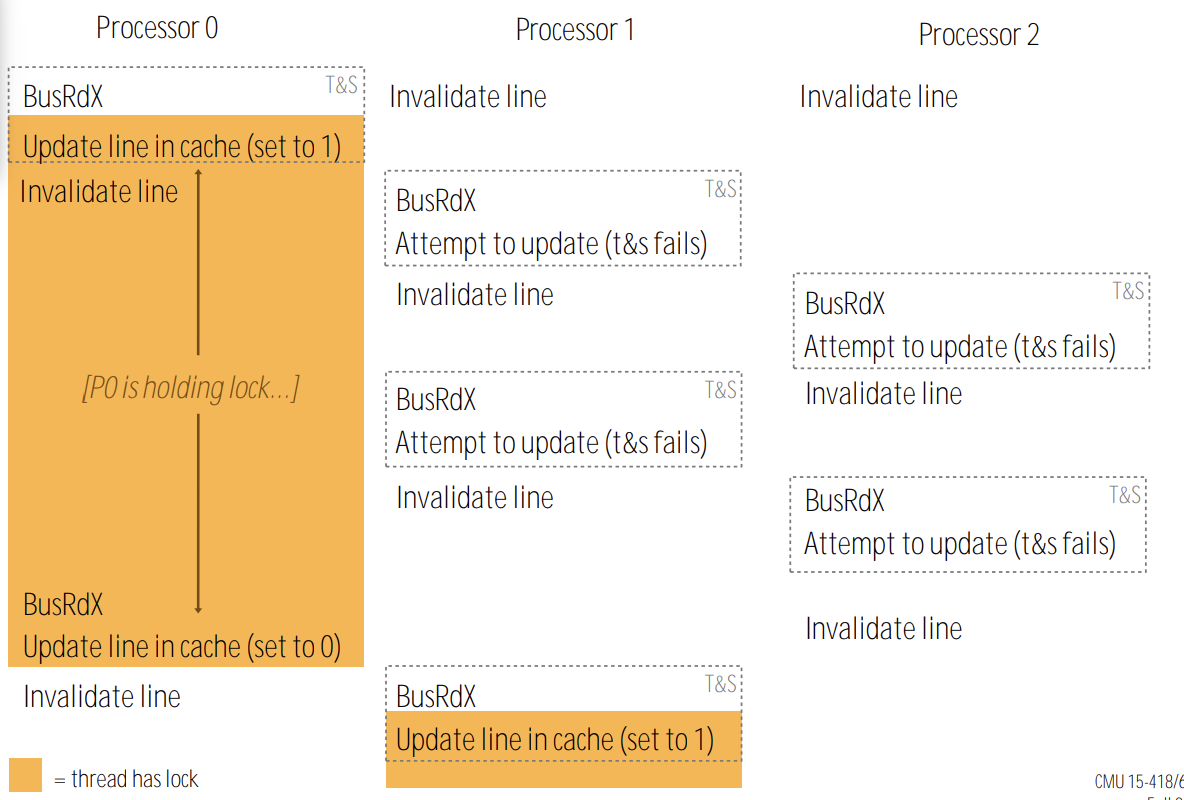
With the increasing of processors, bus contention increases. Lock holders must wait to acquire bus to release.
2.2. lock performance characteristics
- low latency under no contention
- low interconnect traffic
- scalability
- latency and traffic should scale reasonably
- low storage cost
- fairness
- avoid starvation or substantial unfairness
2.3. test-and-test-and-set lock
idea: change RdX to Rd
1 | |
- slightly higher latency
- much less interconnect traffic
- more scalable (due to less traffic)
- low storage cost
- no provisions for fairness
2.4. test-and-set lock with back off
1 | |
- same uncontended latency, but potentially higher latency under contention
- less traffic
- improves scalability
- low storage cost
- exponential back-off can cause severe unfairness
- newer requesters back off for shorter intervals
2.5. ticket lock
thundering herd (惊群效应): upon release, all processors waiting attempt to acquire lock using test-and-set
1 | |
- no atomic operation needed to acquire the lock
- O(P) invalidation per lock release
2.6. array-based lock
idea: each processor spins on a different memory address
1 | |
- O(p) storage space
- O(1) interconnect traffic per release
- atomic circular increment is a more complex operation (slightly higher overhead)
2.7. queue-based lock (MCS lock)
x86 cmpxchg:
1 | |
- idea: create a queue of waiters and each thread allocates a local space on which to wait
- queued spinlocks
- queue head: current lock holder
- queue tail: glock
- operations
- acquire: atomically set tail/glock
- release: if head == tail, holder atomically set the head to NULL using CMPXCHG to release the lock so that other can acquire the lock
1 | |
3. Barriers Implementation
3.1. centralized barrier
buggy version: note that when the first thread clears the flag, some other threads may still waiting in the flag checking loop of the previous barrier
1 | |
solution: use another counter to count the number of threads that have left barrier and clear the flag until all threads leave the barrier.
1 | |
3.2. centralized barrier with sense reversal
Main idea: processors wait for flag to be equal to local sense. Only set flag at exit point when counter == p, no need to clean flag.
1 | |
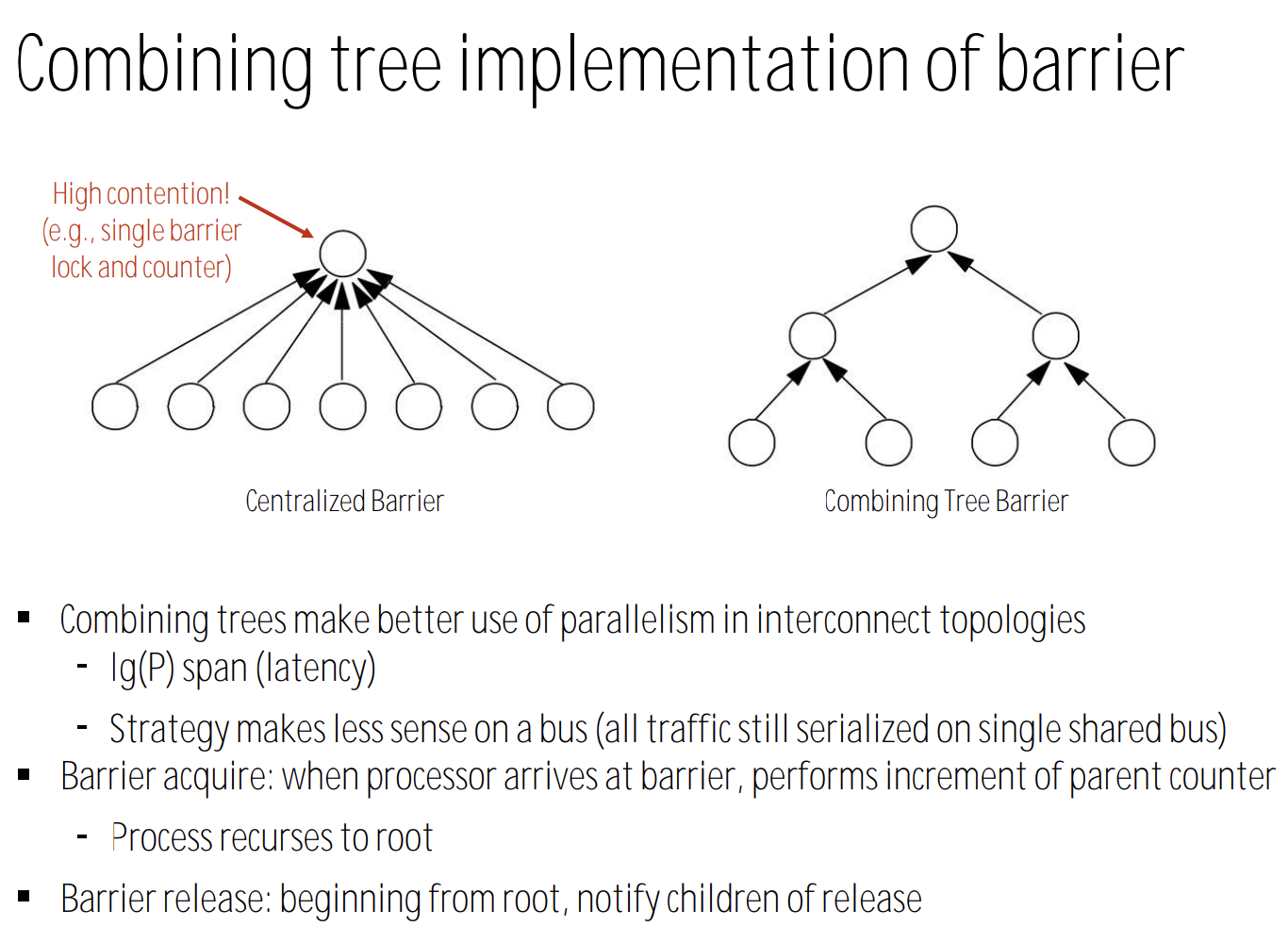
3.3. combining tree implementation of barrier