Optimize the part of the program taking the most time.
高性能计算的目标
- 均衡负载
- 减少通信开销
- 通过各种方法提高并行性,减小串行任务的占比(Amdahl’s law)
parallel programming rules of thumb
- at least as much work as parallel execution capability, generally more independent work than capability
- “parallel slack” = ratio of independent work to machine’s parallel execution capability(~8)
1. 性能优化1: Work distribution and scheduling
Always implement the simplest solution first, then measure performance to determine if you need to do better
1.1. 任务分配
- 静态分配
- 工作的数量和执行时间一定
- 工作的数量一定,执行时间不同但可预测
- 分配方式
- blocked assignment
- interleaved assignment
- 半静态分配
- 工作的执行时间在未来一段时间可预测,根据工作开销周期性调整任务的分配
- 动态分配
- 任务的执行时间或者任务的数量不可预测
1.1.1. 动态分配1: 共享任务队列
- one shared queue, multiple work threads
- tradeoff: task granularity
- small granularity -> better workload balance, more synchronization cost
- large granularity -> minimize overhead of managing the assignment
- ideal granularity depends both on the workload and the mahcine
- scheduler: long task first
1.1.2. 动态分配2: 分布式任务队列
- set of work queues, same amount of worker threads
- the initial assignment of tasks is just like the static assignment
- on demand assignment later
- steal: 若本地任务队列为空,能够从其它任务队列中获取
- 性能特点
- steal阶段存在同步开销
- 增加locality
- 其它设计问题
- who to steal from?
- Generally randomly pick one to steal from.
- how much to steal?
- how to detect program termination?
- how to ensure local queue access is fast?
- who to steal from?
1.2. fork-join并行
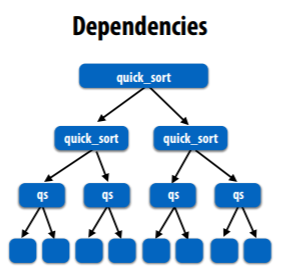
idea: consider divide-and-conquer algorithms, we treat each node as a single task.
cilk_spawn: create new logical thread of controlcilk_sync: join- program termination semantics
- implicit
cilk_syncat the end of every function: returns when all calls spawned by current function have completed
- implicit

- main idea: expose independent work to the system using
cilk_spawn
1.2.1. click运行时实现: locality-aware work stealing scheduler
- strawman
- launch thread for each
cilk_spawnusingpthread_create - for each
cilk_syncusingpthread_join - problems
- heavy cost of spawning
- more running threads than cores
- context switching
- larger working set, less cache locality
- launch thread for each
real world: thread pool + per thread work queue + steal continuation + random victim
- thread pool initialization: all threads created when encountering the first call to
cilk_spawn - nubmer of threads: equal to the number of execution contexts in the machine
- work: 整个上下文,例如下图中的
child(foo()),以及之后的bar();都
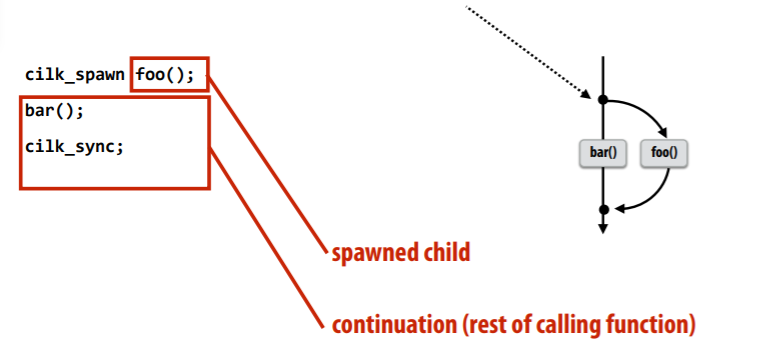
continuation first (child stealing)
- put child context into work queue
- bfs: O(N) space for spawned work
child first (continuation stealing)
- put continuation context into work queue
- dfs: anticipate divide and conquer parallelism, code at right generates work in parallel
- storage space: for T threads, no more than T times that of stack storage for single threaded execution
- exectuion order: same as the program with spawn removed
other implmentation details
- work queue: lock free dequeue
- work stealing: random choice of victim
- local thred pushes/pops from the “tail”
- remote threads steal from “heap”
remote threads steal from top of dequeue
- reduces contention with local threads
- amortize steal cost: steals work at beginning of call tree so that steal longer task, amortize steal cost with future computation
- maximize locality: local thread work on local part of call tree
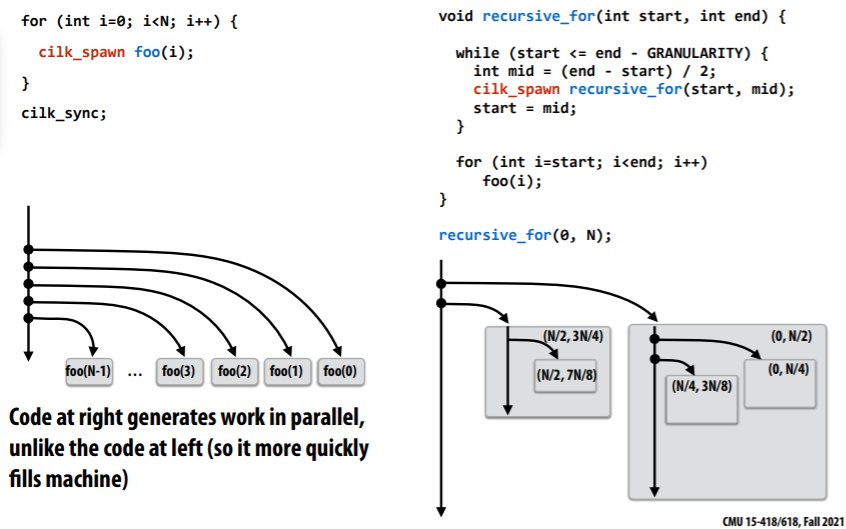
如上图,steal continuation倾向于为同一root的多个子任务生成并行执行的task,而steal child则继续执行root节点,直到将同一root的子任务扔到同一个queue中。
2. 性能优化2: 局部性,通信和竞争
2.1. communication
- 同步(blocking)send/recv
- 异步(non-blocking)send/recv
2.1.1. 通信模型
- non-pipelined communication
- transfer time: $T(n) = T_0 + \frac{n}{B}$
- T0: start-up latency
- n: bytes transferred in operation
- B: transfer rate, bandwidth of the link
- effective bandwidth: $\frac{n}{T(n)}$
- a more general model of communication
- total communication time = overhead + occupancy + network delay
- overhead: time spent on the communication by a processor
- occupancy: time for data to pass through slowest component of system, $T_0 + n/B_{smallest}$
- network delay: everything else
- pipelined communication
- total communication cost = communication time - overlap
- overlap: portion of communication performed concurrently with other work
存在两种类型的通信开销
- inherent communication: communication that must occur in a parallel algorithm, information that fundamentally must be moved between processors to carry out the algorithm
- reduce: work assignment decisions
- artificial communication: all other communication
- 示例
- 系统有最小传输粒度,导致只需要4字节浮点数的程序,需要装载整个64字节cache line
- 分布式内存中数据的分布位置: 由于数据的位置远离最常访问它的处理器,因此导致不必要的通信开销
- 有限的replication capacity: 相同的数据需要通信多次
- 示例
2.1.2. metrics
- communication-to-computation ratio
- amount of communication / amount of computation
- arithmetic intensity
- 1 / communication-to-computation ratio
- improve arithmetic intensity
- schedule threads working on the same data structure at the same time on the same processor
- reduce inherent communication
- ex. CUDA thread block
2.2. contention
- distributed work queues
- grid of particles data structure on large parallel machine
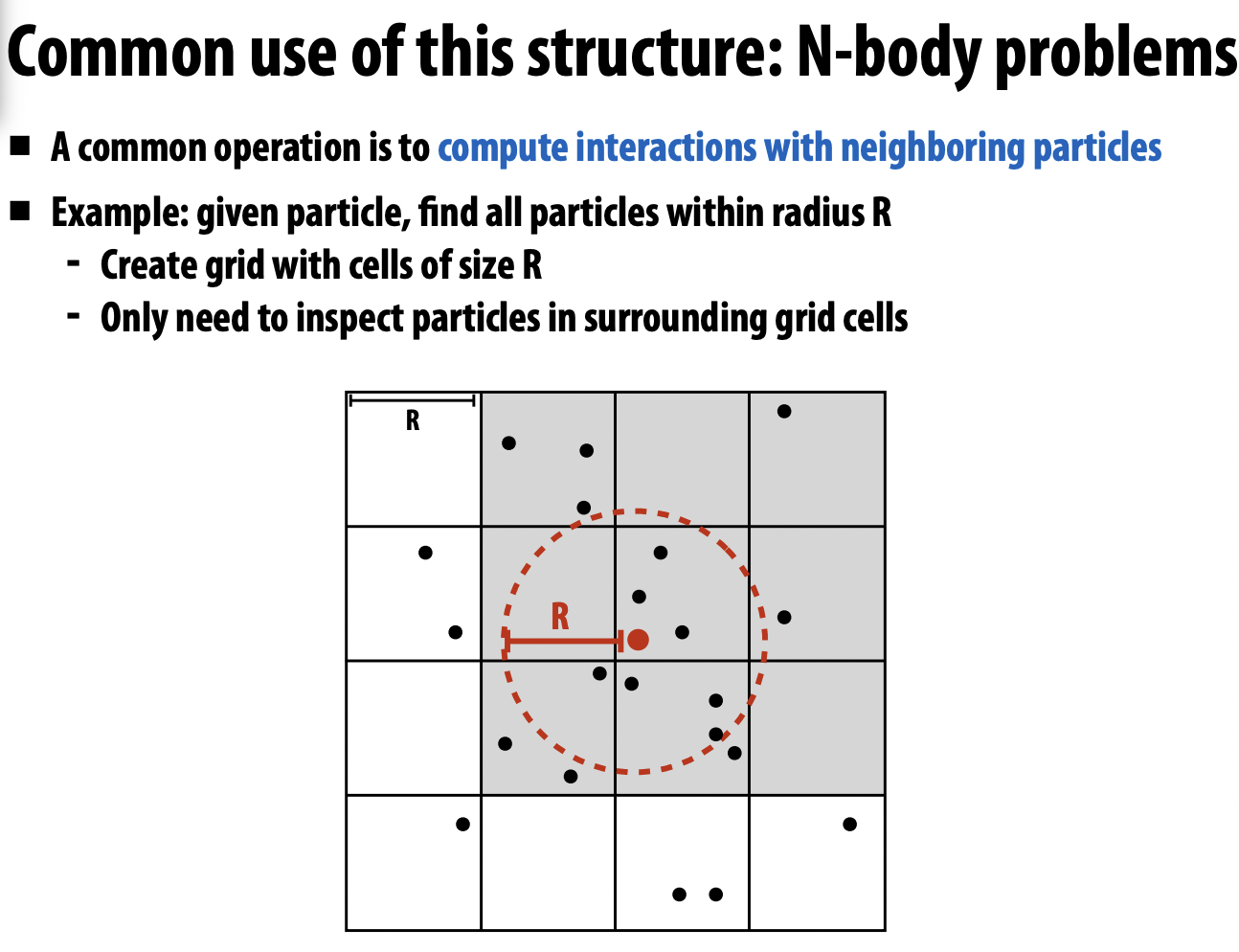
目标: 计算各个cell中包含哪些particles
- 方法一: 针对每个cell,串行判断各个particles
- work inefficient: 16x额外的工作
- parallelism inefficient: 仅16个并行任务
- 方法二: 针对每个particles,判断所在cell,然后原子更新cell列表
- massive contention
- 各个cell列表公用同一个锁
- 各个cell列表使用细粒度的锁
- massive contention
- 方法三: 计算部分结果,最后合并
- 方法四: 数据并行方法
- 计算每个particle所在的cell,以particle为索引填充数组(particle index, grid index)
- 对该数组排序根据grid index
- 对该数组每个元素,并行获取每个cell在数组中的起始索引和结束索引
2.3. reduce communication costs
- reduce overhead of communication to sender/receiver
- send fewer message, make messages larger, amortize overhead
- batch small messages into large ones
- reduce delay
- programmer: utilize locality in code
- hw implementor: improve communication architecture
- reduce contention
- replicate contended resources (local copies, fine-grained locks, per thread queue)
- stagger access to contended resources
- increase communication/computation overlap
- programmer: use async communication
- hw implementor: pipelining, multi-threading, pre-fetching, out-of-order
3. 小结: parallelization workflow
- decomposition
- assignment
- load balancing
- maximize locality
- minimize extra work, eg. contention, communication
- orchestration
- mapping