在所有的弱点中,最大的弱点就是害怕出现弱点。
1. CUDA 抽象
- 线程层次结构
- two-level hierarchy
- thread blocks
- threads
- 由程序员显示指定每一维的大小
- 每个block各个维度的thread数
- 总的block维度
- two-level hierarchy
- 分布式地址空间
- GPU和CPU地址空间通信,memcpy primitive:
cudaMemcpy - 三种设备内存
- per block mem: software controlled
__shared__: shared memory for per block threads
- per thread mem: regs
- device global mem
cudaMalloc
- per block mem: software controlled
- barrier原语:
__syncthreads()同步同一线程块的线程 - atomic operations: 访问全局内存地址或者块内共享内存地址的原子操作
- GPU和CPU地址空间通信,memcpy primitive:
2. CUDA 硬件实现
2.1. 编译和任务分配
- CUDA设备二进制
- 程序指令
- 需要的硬件资源
- 块内线程数
- 线程本地数据
- 线程块共享数据
- 编译器编译时限制内存以及块内线程数,对于超出可获得资源的程序,无法通过编译
- CUDA线程块分配
- assumption: 线程块的执行能以任何顺序进行
- thread block scheduler动态分配thread block到硬件block
2.2. 硬件细节
- warp: 能够同时(并发)执行的独立指令流数量,即需要同时执行相同指令的cuda thread的数量
- 对于Nvidia GPU而言每个指令流运行宽度为32的指令,因此每个warp对应32个thread
- 每个时钟周期从所有warps中选择
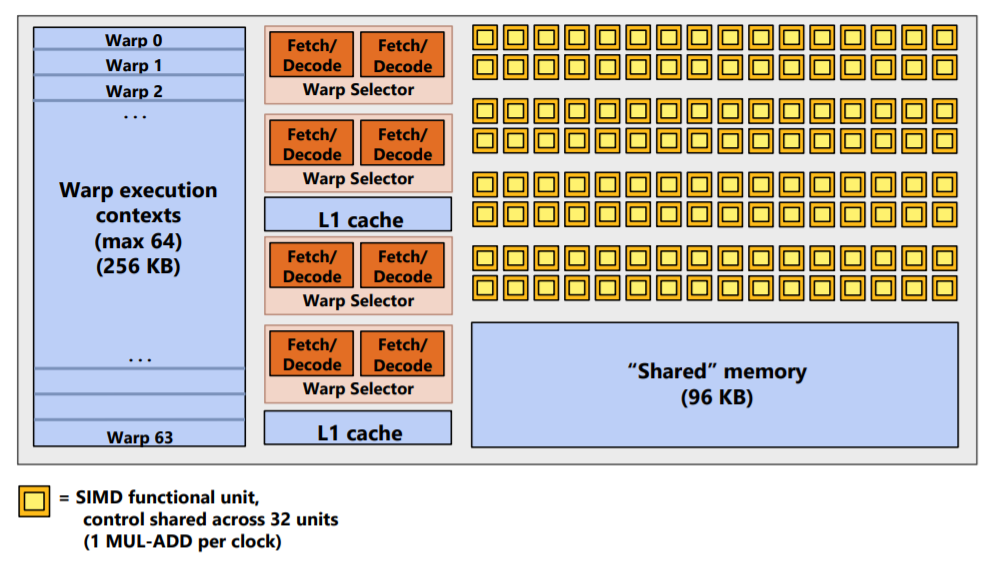
如上图的单个GPU thread block(SMM core, Streaming Multiprocessor)所示,其内共有4核,64个执行上下文
- 64 warp: 64路multi-threading
- 32-wide SIMD
- 2-wide ILP within a single thread
- 每个周期可以从64个warp执行上下文中选择4个warp
- 每个warp选择最多2个可运行指令(指令级别并行)
- 能够并行运行总共$4 * 32 = 128$个cuda thread
NVIDIA GTX 980有16个上述SMM核
- $16 * 128 = 2048$SIMD mul-add ALUs
- 最多$16 * 64 = 1024$ interleaved warps($1024 * 32 = 32,768$ CUDA threads)
调度:
- block scheduler将block分配到SMM。单个SMM能容纳的block数量取决于SMM中的warp资源和block memory资源。单个SMM核可能执行多个CUDA block。
- SM中单个核的warp selector选择执行的warp/32个cuda threads
注意: 调度单元和编程抽象单元是block和thread,调度器负责将整数个block分配到warp存储中。
- 注意1: GPU无法抢占threads。一旦资源设置好,threads会run to completion。
- 注意2: GPU线程间是可能有依赖的,因此有
__syncthreads,atomicAdd等原语,但是GPU调度器不能保证调度的顺序
2.3. 什么是warp
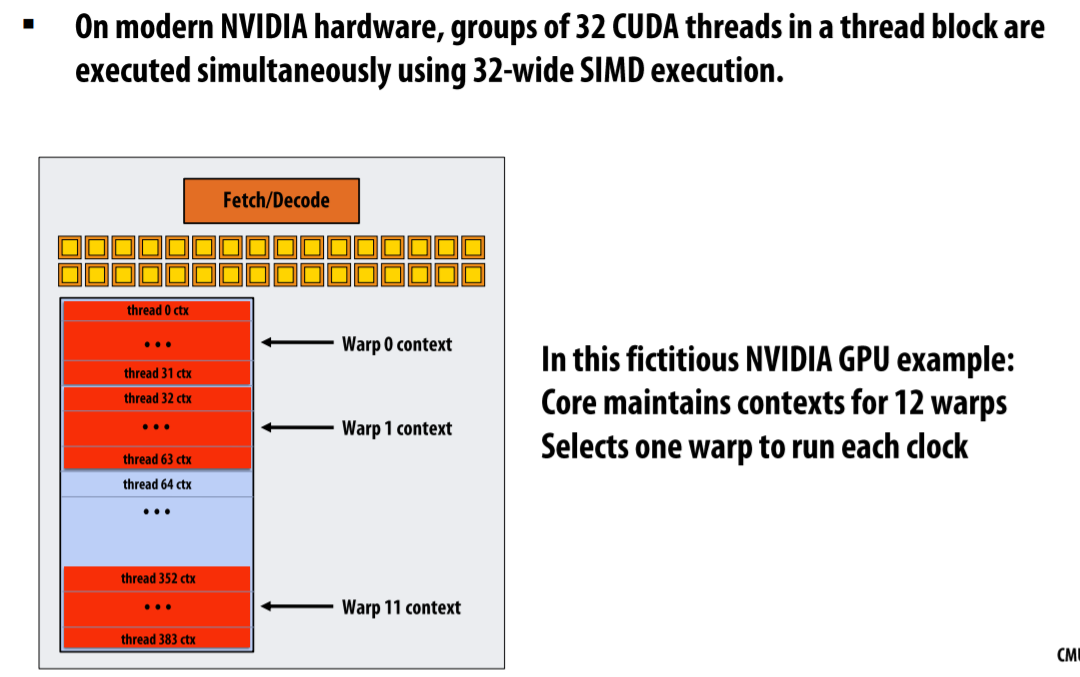
- GPU side: 32个被相同SIMD指令执行的上下文
- CPU side: 单个运行32-wide SIMD指令的执行上下文