我活着不是为了满足你的期望,正如你也不是因为我的期望而活着。
1. 并行形式
- instruction level parallelism (ILP)
- superscalar: 通过使用多个硬件单元,在每个时钟周期执行多个操作
- out of order: 乱序处理器有顺序(in-order)的前端(fetch+decode)和commit部分
- latency bound: 根据dataflow图的依赖关系,关键路径给出的每次迭代需要的延迟数。
- throughput bound: 在不考虑数据流依赖和指令调度的情况下,由执行单元数以及发射速率决定的每次迭代需要的CPU周期数。
- 例如,若每次迭代需要执行8条add/mul指令,而有2个能每周期执行一条add/mul指令的单元, 则throughput bound为4,即最快4个周期执行完所有8条指令
- structural hazards: 数据已经就绪了,但是没有足够的硬件单元执行对应的指令
- multi-cores
- 为了增加核数,需要减小每个核占用的面积,每个核可能性能较低
- SIMD processing: use multiple ALUs controlled by same instruction stream
- instruction coherence: whether the conditional behaviors are similar across all parts of the instruction stream
- divergent execution: a lack of instruction stream coherence
- explicit SIMD: 修改源文件,在编译期生成SIMD指令
- implicit SIMD: 编译器仍生成使用标量指令的二进制文件,但是GPU硬件负责在不同数据的多个实例上执行相同的指令
- instruction coherence: whether the conditional behaviors are similar across all parts of the instruction stream
2. 内存访问
- memory latency: the amount of time a memory request from a processor to be serviced by the memory system
- memory bandwidth: rate at which the memory system can provide data to a processor
- deal with memory latency
- prefetch
- hardware recognize stride access
- multi-threading: 1 core multiple hardware threads
- main idea: 通过在等待内存操作时切换执行另一个hardware thread隐藏内存访问的延迟。具体而言,借助多份寄存器文件,当一个hardware thread stall的时候,可以使用另一份寄存器文件运行另一个hardware thread
- 注意: 只能运行来自相同进程的线程,且并非同时执行,同一时刻只能执行一个hardware thread
- trade off: more hardware threads <-> more cache size
- hyperthreading/simultaneously multiple processing
- 除了寄存器文件,使用额外的硬件,同时执行多个线程
- 注意: 从os的角度,hyperthreading可以运行来自不同进程的线程
- prefetch
注意: prefetch和multi-threading都是延迟隐藏(latency hiding)技术,而不是延迟减少技术(latency reducing)。
2.1. memory bandwith limit
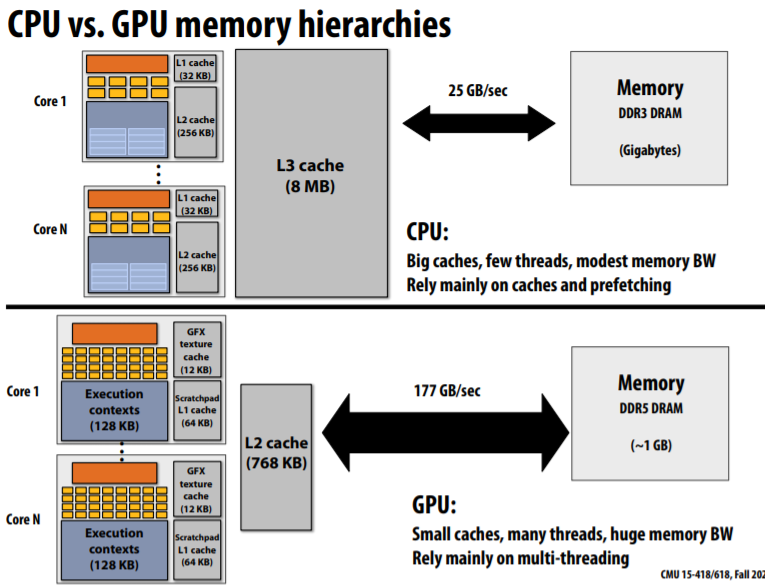
假设现在有向量乘法需要执行,需要两个load操作,一个MUL操作和一个store操作。对于NVIDIA GTX 480 GPU,每个MUL操作宽度为12字节,每个时钟周期能够完成480个MUL操作(1.2GHz),因而处理带宽约为6.4TB/s,但是内存带宽仅为177GB/s。因此,只能达到3%的效率。
由此可见,当使用了multi-threading、SIMD技术后,内存带宽是根本限制。
- fetch data from memory less often
- 数据重用: temporal locality
- 线程间协作: share data across threads
- request data less often
- arithmetic intensity: ratio of math operations to data access operations in an instruction stream
- main point: programs must have high arithmetic intensity to utilize modern processors efficiently
3. 并行编程的抽象和实现
根据并行实体间通信方式的不同,并行编程包括三种模型。
3.1. 模型1: 共享地址空间
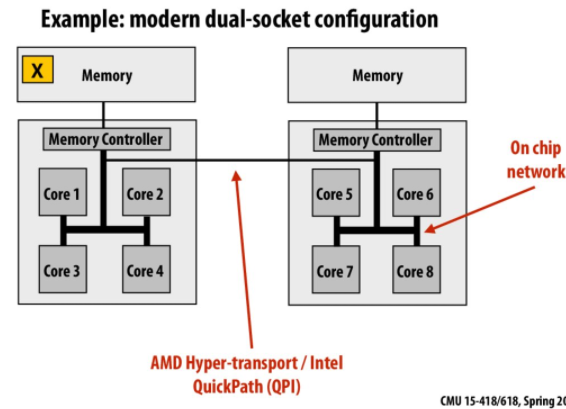
任何处理器能够直接访问整个地址空间。注意是处理器级别(不是核级别)。
- 共享地址空间可以有多种架构
- symmetric (shared-memory) multi-processor (SMP)
- uniform memory access time: 对所有处理器而言,不考虑cache的情况下,访问内存的时间相同
- non-uniform memory access (NUMA)
- 不同处理器对内存访问延迟不同
- pro: 系统扩展性更好
- con: tuning的复杂度
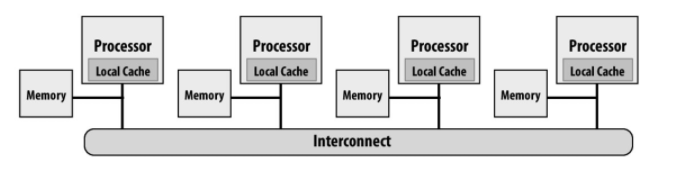
3.2. 模型2: 消息传递
- 线程在自己私有地址空间工作
- 线程间通信通过明确的send/recv消息进行
- send: 接收者,发送数据的buffer,消息标识符
- receive: 发送者,接收数据的buffer,消息标识符
- MPI
3.3. 模型3: 数据并行
严格的执行模型: 并行实体执行在不同的数据元素上执行相同的函数。
- 历史上: 对数组中的每个元素执行相同的操作
- SIMD supercomputer: 几千个处理器只支持SIMD指令
- connection machine: 几千个处理器,单个指令解码单元
- cray超级计算机(向量处理器)
- 目前: SPMD programming
map(function, collection)- 注意: 数据并行模型对并行实体的执行没有任何顺序保证
- 实现: ISPC, CUDA, OpenCL
3.3.1. SPMD抽象: ISPC实现
对于ISPC,可以将循环体视作function,这些function被分配给并行实体。
- SPMD(single program multiple data): 编程模型
- 抽象: 对ISPC函数的调用会生成 “a gang of ISPC program instances”。所有实例并发运行ISPC代码。
- 实现: ISPC编译器生成SIMD指令,program instance数量是硬件SIMD宽度的倍数
- programCount: Number of simultaneously executing instances in the gang.
- programIndex: id of the current instance in the gang
- uniform: type modifier. All instances have the same value for this variable.
- foreach
- 任务划分
- blocked assignment: 连续的块分配给单个并行实例,需要使用
gather指令 - interleaved assignment: 每个单元依次分配给每个并行实例,只需要packed load指令
_mm_load_ps1- ISPC的
foreach使用interleave assignment
- ISPC的
- blocked assignment: 连续的块分配给单个并行实例,需要使用
3.3.2. stream programming model
- streams: sequences of elements。流中的元素可以独立处理。
- kernels: side-effect-free functions.
1 | |
- pros: 编译器更易于优化
- 并行: 由于kernel无副作用,且流中数据无依赖,因此可以并行执行
- prefetch: 输入输出在调用执行前就可以知道,因此可以通过prefetch隐藏内存访问延迟
- 节省带宽: 生产者、消费者依赖提前知道,可以通过on-chip缓存/cache在得到结果后立刻开始执行,中间结果不用写内存
3.3.3. gather/scatter: 数据并行原语
- CPU/GPU SIMD指令支持
- 示例: interleaved数组操作
- gather: 根据索引向量从输入向量中获取对应元素组成中间向量->对中间元素进行运算->输出向量
- scatter: 输入向量->运算->将计算结果根据索引向量映射到输出向量
4. 并行编程基础
- identify work that can be performed in parallel
- partition work
- manage data access, communication, and synchronization
并行程序的模式
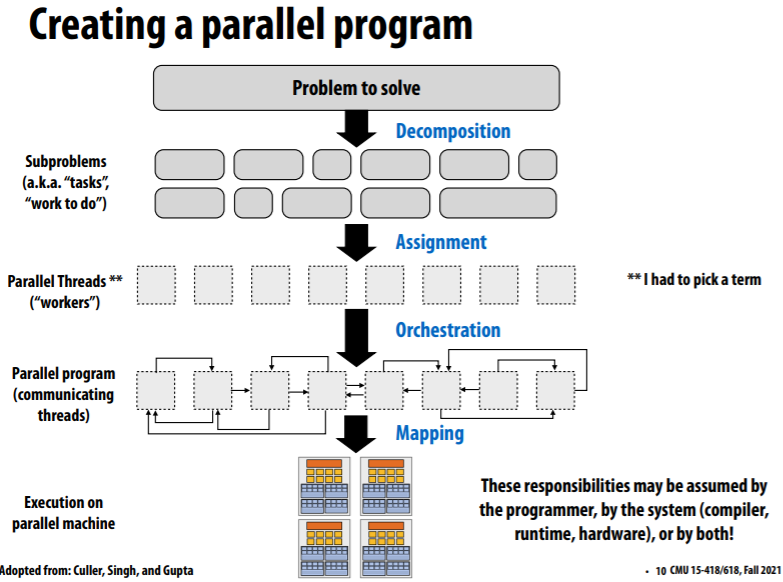
4.1. decomposition
- main idea: 从high level,找到问题中的依赖以尽可能利用并行性,即create at least enough tasks to keep all execution units on a machine busy
4.1.1. Amdahl’s law
- s是程序中只能顺序执行部分,p是处理器核心数
- 最大并行加速比为$\lt\frac{1}{s}$
- 并行加速比受限于程序可并行部分的比例
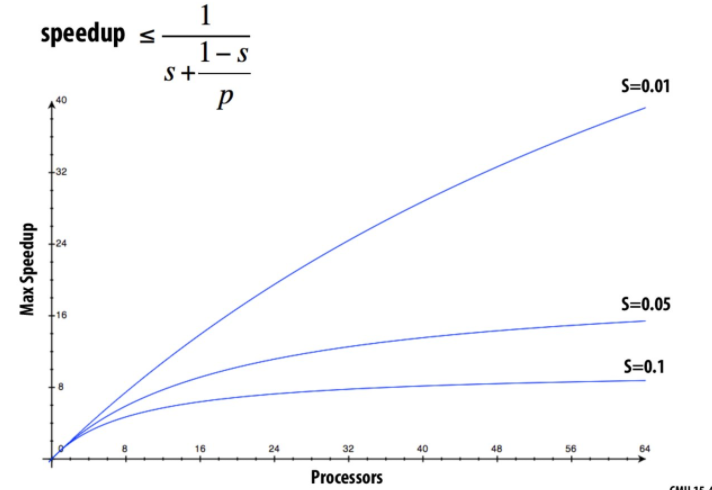
如上图所示,当顺序比例为10%时,即使使用64个处理器,加速比也只为8。
4.2. assignment
- 为并行实体分配任务
- goals:
- balance workload
- reduce communication costs
- static assignment
- assign by programmers
- ISPC:
foreach - 使用pthreads
- dynamic assignment
- ISPC: 由ISPC运行时分配任务给工作线程
launch[100] my_ispc_task(input, output, n)- 分配策略: 当前任务执行完后,执行实例查看任务列表并选择下一个未完成的任务。
- ISPC: 由ISPC运行时分配任务给工作线程
4.3. orchestration
- 主要内容
- 通信
- 同步机制
- 任务调度
- goal: 减少通信/同步的开销,保持数据访问的局部性,减少开销
- handled by programmer
- lock
- barrier
- handled by system
- communication primitives
4.4. mapping
- by os
- eg. map pthread to HW execution context on a CPU core
- by the compiler
- eg. map ISPC program instances to vector instruction lanes
- by the hardware(GPU)
- eg. map CUDA thread blocks to GPU cores
示例: 2D grid solver
data parallel 解法
for_allreduceAll: 内置通信原语
shared address space 解法
lockbarrier
消息通信 解法
- 数据块级别的send和recv
- 同步send/recv
- 死锁的解决: 偶数线程send,基数recv;然后反过来
- 异步send/recv
- send: 调用立即返回
- recv: 发布在未来会被接收的内容,立即返回